
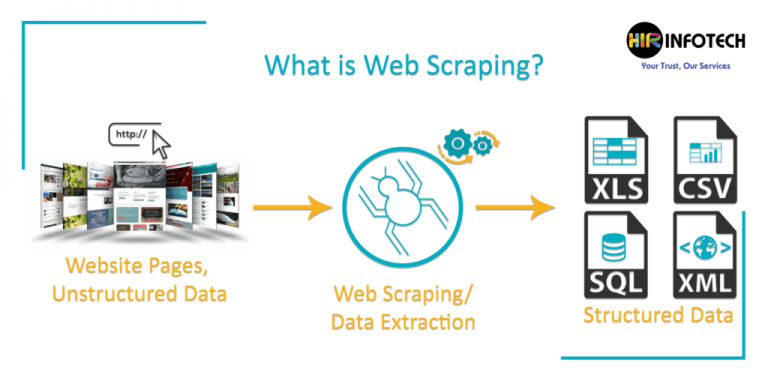
What is Web Scraping
Web scraping typically extracts large amounts of data from websites for a variety of uses such as price monitoring, enriching machine learning models, financial data aggregation, monitoring consumer sentiment, news tracking, etc. Browsers show data from a website. However, manually copy data from multiple sources for retrieval in a central place can be very tedious and time-consuming. Web scraping tools essentially automate this manual process.

Basics of Web Scraping
“Web scraping,” also called crawling or spidering, is the automated gathering of data from an online source usually from a website. While scraping is a great way to get massive amounts of data in relatively short timeframes, it does add stress to the server where the source hosted.
Primarily why many websites disallow or ban scraping all together. However, as long as it does not disrupt the primary function of the online source, it is relatively acceptable.
Despite its legal challenges, web scraping remains popular even in 2019. The prominence and need for analytics have risen multifold. This, in turn, means various learning models and analytics engine need more raw data. Web scraping remains a popular way to collect information. With the rise of programming languages such a Python, web scraping has made significant leaps.
Typical applications of web scraping
Social media sentiment analysis
The shelf life of social media posts is very little. However, when looked at collectively, they show valuable trends. While most social media platforms have APIs that let 3rd party tools access their data, this may not always be sufficient. In such cases scraping these websites gives access to real-time information such as trending sentiments, phrases, topics, etc.
E-Commerce pricing
Many E-Commerce sellers often have their products listed on multiple marketplaces. With scraping, they can monitor the pricing on various platforms and make a sale on the market where the profit is higher.
Investment opportunities
Real estate investors often want to know about promising neighborhoods they can invest in that. While there are multiple ways to get this data, web scraping travel marketplaces and hospitality brokerage websites offer valuable information. It includes information such as the highest-rated areas, amenities that typical buyers look for, locations that may be upcoming as attractive renting options, etc.
Machine learning
Machine learning models need raw data to evolve and improve. Web scraping tools can scrape a large number of data points, text and images in a relatively short time. Machine learning is fueling today’s technological marvels such as driverless cars, space flight, image and speech recognition. However, these models need data to improve their accuracy and reliability.
A good web scraping project follows these practices. These ensure that you get the data you are looking for while being non-disruptive to the data sources.
Identify the goal
Any web scraping project begins with a need. A goal detailing the expected outcomes is necessary and is the most basic need for a scraping task. The following set of questions need to ask while identifying the need for a web scraping project:
- What kind of information do we expect to seek?
- What will be the outcome of this scraping activity?
- Where this information is typically published?
- Who are the end-users who will consume this data?
- Where will the extracted data be stored? E.g., on Cloud or on-premise storage, on an external database, etc.
- How should this data be presented to its end-users? E.g., as a CSV/Excel/JSON file or as an SQL database, etc.
- How often are the source websites refreshed with new data? In other words, what is the typical shelf-life of the data? That collected and how often does it have to be updated?
- Post the scraping activity, what are the types of reports you would want to generate?
Tool analysis
Since web scraping is mostly automated, tool selection is crucial. The following points need to be kept in mind when finalizing tool selection:
- Fitment with the needs of the project
- Supported operating systems and platforms
- Free/open-source or paid tool
- Support for scripting languages
- Support for built-in data storage
- Available selectors
- Availability of documentation
Designing the scraping schema
Let’s assume that our scraping job collects data from job sites about open positions listed by various organizations. The data source would also dictate the schema attributes. The schema for this job would look something like this:
- Job ID
- Title
- Job description
- URL used to apply for the position
- Job location
- Remuneration data if it is available
- Job type
- Experience level
- Any special skills listed
Test runs and larger jobs
It is a no-brainer and a test run will help you identify any roadblocks or potential issues before running a more significant role. While there is no guarantee that there will be no surprises later on, results from the test run are a good indicator of what to expect going forward.
- Parse the HTML
- Retrieve the desired item as per your scraping schema
- Identify URLs pointing to subsequent pages
Once we are happy with the test run, we can now generalize the scope and move ahead with a more massive scrape. Here we need to understand how a human would retrieve data from each page. Using regular expressions, we can accurately match and retrieve the correct data. Subsequently, we also need to catch the correct XPath’s and replace them with hardcoded values if necessary. You may also need support from an external library.
Often you may need external libraries that act as inputs on the source. E.g., you may need to enter the Country, State and Zipcode to identify the correct values that you need.
Here are a few additional points to check:
- Command-line interface
- Scheduling for the created scrape
- Third-party integration support (E.g., for Git, TFS, Bitbucket)
- Scrape templates for similar websites
Output formats
Depending on the tool, end-users can access the data from web scraping in several formats:
- CSV
- JSON
- XML
- Excel
- SQL Server database
- MySQL Database
- OleDB Database
- Script (A script provides data from almost any data source)
Improving the performance and reliability of your scrape
Tools and scripts often follow a few best practices while web scraping large amounts of data.
In many cases, the scraping job may have to collect vast amounts of data. It may take too much time and encounter timeouts and endless loops. Hence tool identification and understanding its capabilities are essential. Here are a few best practices to help you better tune your scraping models for performance and reliability.
- If possible, avoid the use of images while web scraping. If you need images, you must store these in a local drive and update the database with the appropriate path.
- Certain Javascript features can cause instability. Certain dynamic features may cause memory leaks, websites hang or even crashes. It is important to remember that the regular activity of the information source must not disrupt in any way. In such scenarios, a few tools use web crawler agents to facilitate the scrape. Very often, using a web crawler agent can be up to 100 times faster than using a web browser agent.
- Enable the following options in your scraping tool or script – ‘Ignore cache,’ ‘Ignore certificate errors,’ and ‘Ignore to run ActiveX and flash.’
- Call a terminate process after every scrape session is complete
- Avoid the use of multiple web browsers for each scrape
- Handle memory leaks
Things to stay away from
There are a few no-no’s when setting up and executing a web scraping project.
- Avoid sites with too many broken links
- Stay away from sites that have too many missing values in their data fields
- Sites that require a CAPTCHA authentication to show data
- Some websites have an endless loop of pagination. Here the scraping tool would start from the beginning once the number of pages exhausts.
- Web scraping iframe-based websites
- Once a certain connection threshold reaches, some websites may prevent users from scraping it further. While you can use proxies and different user headers to complete the scraping, it is vital to understand the reason why these measures are in place. If a website has taken steps to prevent web scraping, these should be respected and left alone. Forcibly web scraping such sites is illegal.
Web scraping has been around since the early days of the internet. While it can provide you the data you need, certain care, caution and restraint should exercise. A properly planned and executed web scraping project can yield valuable data – one that will be useful for the end-user.



 7346
7346

*********6@weepm.com
This website, https://www.airslate.com/bots/jira, is without a doubt one of my favourites. The main reason is the stuff they supply. strongly suggested